In this age of the internet, you must have encountered one or the other form of Machine Learning (ML). It can be a simple captcha, language translation or all the advertisements that you see on various websites. ML has become a part of our daily lives. This blog post is about a special type of ML method called ‘recommender system’ that has been heavily used in making recommendations to the user under various contexts. The most popular examples of this kind of method are movie recommendations made by Netflix1, item listings by Amazon 2, next song selection by Spotify3, photo recommendations by Instagram4 and the list goes on. Hence, it is not surprising that many of the ML modules use a recommender system to explain the basic concepts of ML. Here I will explore one such recommender system using a highly accessed database named MovieLens. I will construct a simple recommender system, which will make movie recommendations based on available data.
The Strategy
The MovieLens database is used by thousands of people around the world to create recommender systems using similar techniques. In this blog post, I will portray two distinct scenarios where I can implement various concepts of Recommender System (See Fig 1).
 |
| Fig 1: Two different scenarios used in this analysis. |
Following is an overview of the data stored in the MovieLens database (as of 1 Oct 2020),
| Description |
Value |
| Number of movies |
27022 |
| Number of categories |
19 |
| Release year |
1894 to 2015 |
| Number of ratings |
20000263 |
| Number of users |
138493 |
Content-Based Filtering
In this method, we will find movies ‘similar’ to the user input. One can provide a movie name as input and the algorithm will predict movies with similar attributes. The method will gather all the information about this movie like its genre, tags etc. given by other users, and then generate a matrix of these attributes. This workflow is shown in Fig 2 and the source code for the method can be found here.
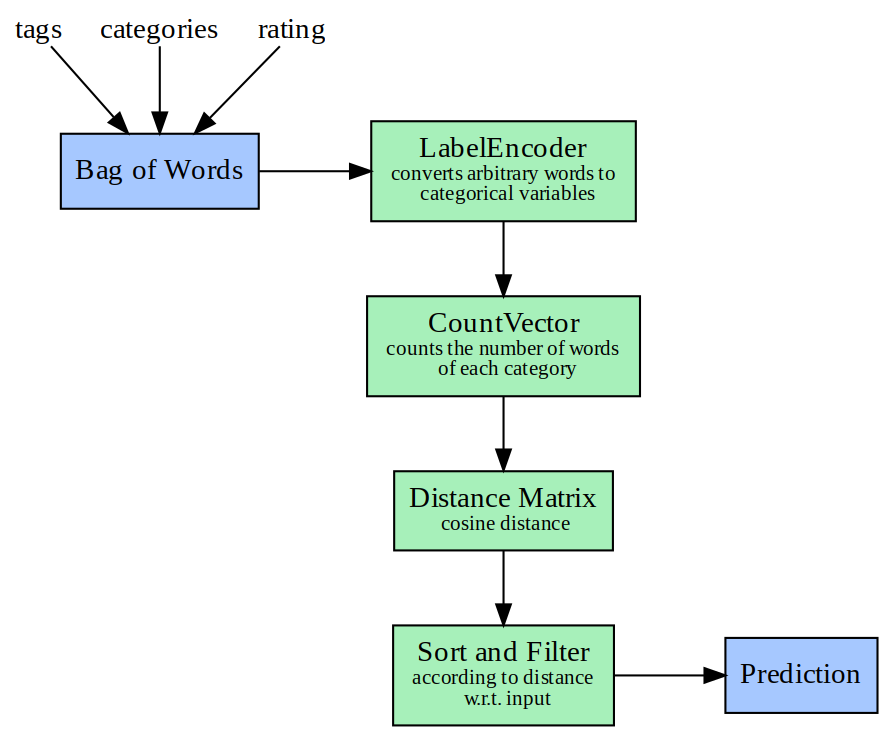 |
| Fig 2: Steps in content-based filtering method. |
This code will generate the cosine-similarity 5 matrix between every movie based on their tags and genres. When the user inputs a movie name, it will be searched in the cosine-similarity matrix, and a list of movies that are most similar to each other will be retrieved. Moreover, the list will be reordered based on their similarity score. Another simple tweak I did was reduce the weight of genre in calculating final distance. It improved our similar movie predictions. Following are some results from this method:
| Input Movie |
Similar Movies (top 3, in order) |
| Spider-Man |
Spider-Man 2, Spider-Man 3, X-Men |
| The Shawshank Redemption |
The Godfather, The Green Mile, Mystic River |
| Toy Story |
Toy Story 2, Finding Nemo, Monsters, Inc. |
| The Grudge |
The Haunting , The Ring, The Amityville Horror |
| The Wolf of Wall Street |
Mr. Nice, Spun, Trainspotting |
| The Notebook |
Blue Valentine, Titanic, The Vow |
| Memento |
Se7en, The Usual Suspects, The Game |
In my opinion, these predictions are quite accurate. In most of the searches, the output movies are similar to that of the input in one respect or the other. This suggests that the tagging done by the users is pretty good and the cosine-similarity matrix is working as expected. In the future, we can expand this method by taking multiple movies as input and predicting movies similar to this movie group.
Advice for large data
The generation of the cosine-similarity matrix for a huge number of movies is a very time-consuming and computationally expensive task. Before executing such a job, do review your system configuration. It will need a huge amount of free RAM access depending on the number of movies and ratings you are using. In such cases, it is a good idea to save the matrix on the disk (for example, in HDF5 file format) and access it for your future predictions.
User-Based Filtering
Content-based filtering provides good recommendations, given any movie as an input. However, the most important limitation of this method is that we will never get a cross-genre movie prediction. This is where user-based filtering will help us. In this method, we will train the neural network that will predict movie ratings based on the history of ratings given by a user. With this method, the user will provide names of movies and their ratings. Our model will predict movies that the user might like. This strategy is shown in Fig 3.
 |
| Fig 3: Steps in user-based filtering method. |
The Neural Network
I will not go into the details of how the neural network was designed. There are plenty of blogs to tackle each aspect of this process, including how to improve accuracy, speed and computing time. I have used keras functional programming to build the model (Fig 4). In this model, I have used Embedding layers to represent big input matrices in lower dimensions. I have projected all inputs on to an arbitrarily selected number of dimensions (here, 16), and in-turn concatenated them, Finally, I have added a hidden and an output layer (see Fig 4).
 |
Fig 4: The Neural Network generated in keras |
I have normalised the user ratings to a scale of 0-1. Other parameters like an epoch, loss function, batch size etc. are being used randomly. One should try multiple such parameters to fine-tune their model for better predictions. The history of model accuracy across multiple epochs is shown in Fig 5. The Loss for our model is around 0.024, and thus the accuracy is quite good. The validation loss was also minimal and did not show overfitting.
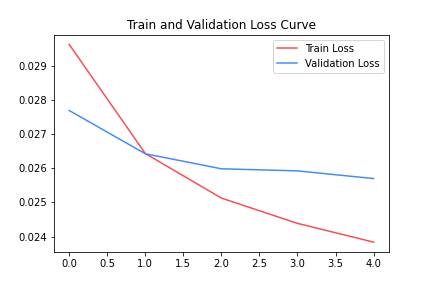 |
| Fig 5: Loss curves for model shown in Fig 4. X-axis represents time (here, epochs) while Y-axis represents Loss. |
Cold-Start Problem for the Neural Network
‘Cold-start problem’ is an age-old problem faced by many recommender systems. My system is no exception. This neural network is trained to accept userId and movieId pair as an input (See Fig 3 and 4). Hence, to get any prediction from the trained model, the user needs to provide userId. This will become an issue if the recommendation is for a new user (who will not have any userId assigned yet).
To circumvent this issue, I decided to search for existing users from the database who can act as a proxy for the new user. Then one can use the userId of the proxy user to get a prediction from the neural network. It can be achieved by generating a cosine-similarity matrix (as in content-based filtering) and finding the most similar user based on their rating history.
Predictions from the Neural Network
Following are some predictions from this model.
| Input Movies [Input Ratings] |
Top 5 Recommendations [Score] |
The Godfather [4.5]
The Godfather: Part III [4] |
The Shawshank Redemption [0.879]
The Usual Suspects [0.866]
Fight Club [0.857]
The Departed [0.836]
American History X [0.832] |
Batman Begins [4.5]
Batman: Assault on Arkham [5]
The Avengers [3.5]
Iron Man 3 [4] |
The Sound of Music [0.926]
Anne of Green Gables [0.926]
Pride and Prejudice [0.925]
White Christmas [0.923]
Babylon 5: In the Beginning [0.919] |
Batman Begins [1]
Batman: Assault on Arkham [1]
The Avengers [1]
Iron Man 3 [1] |
The Dark Knight [0.973]
The Usual Suspects [0.952]
The Shawshank Redemption [0.948]
Inception [0.94]
The Matrix [0.939] |
The Haunting [3.5]
The Ring [4]
The Grudge [4.5]
Iron Man 3 [1] |
Ravenous [1.005]
The Devil’s Rejects [0.983]
From Dusk Till Dawn [0.976]
Saw II [0.969]
Cruel Intentions [0.967] |
Toy Story [4.5]
Toy Story 2 [4]
Finding Nemo [3]
Monsters, Inc. [3.5] |
The Civil War [1.015]
Schindler’s List [1.003]
The Shawshank Redemption [0.996]
Band of Brothers [0.994]
Wallace & Gromit: The Wrong Trousers [0.985] |
There is something quite intriguing about the above predictions! When all the inputs are action movies like ‘Batman Begins’, a drama movie like ‘The Sound of Music’ is the first recommendation. This may be due to some users who have highly rated movies from both action and drama genres. Such cross-genre predictions are only possible with user-based filtering.
These predictions point to a few potential issues as well. For example, when I lowered the ratings of action movies like ‘Batman Begins’, this model recommended more action movies like ‘Dark Night’, in contrast to the scenario where those ratings were high and it recommended more drama movies. The next section will explain how one can overcome such issues.
Further improvements
Over- or under-rating is a major issue. Many times users rate consistently higher or lower for specific genres. It creates a bias while training a neural network. It can lead to an uneven representation of movies in the predictions. To remove such bias, one can use user-level ‘bias-coefficients’ that will scale the user ratings.
As I have normalised ratings from 0 to 1, it will be difficult to represent unpreferred movies. For example, if users do not want any ‘horror’ movies, this neural network does not have any mechanism to consider this information. To tackle this issue, one can shift 0-1 normalization to -1 to 1.
In addition to the above, there are multiple attributes one can utilize to further improve the predictions, like adding more training data regarding movies (e.g. reviews, cast and crew information etc.) or user (e.g. location, country etc.). One can use a mixed strategy where content-based and user-based filtering can be implemented together. One can also use interaction information from the service website (e.g. items clicked, movie selected, trailer watched, review read etc).
Tip: I have constructed many large neural networks. However, due to limitations in computational resources, I could not train them on my 4-year-old laptop. There are plenty of cloud-computing services available, which one can use to get more computing power. I have used Kaggle Notebooks that offered me slightly better computing resources than my laptop. So thank you Kaggle :)
Full code can be found here.
All web links provided in this article are accessed on 1 Oct 2020 (if not mentioned otherwise)
References
- How Netflix’s Recommendations System works - https://help.netflix.com/en/node/100639 [accessed on 1 Oct 2020]
- Real-time personalization and recommendation - https://aws.amazon.com/personalize/ [accessed on 1 Oct 2020]
- Guidelines for surfacing Categorized Content Recommendations in your mobile app - https://developer.spotify.com/use-cases/mobile-apps/content-recommendations/ [accessed on 1 Oct 2020]
- Powered by AI: Instagram’s Explore recommender system - https://ai.facebook.com/blog/powered-by-ai-instagrams-explore-recommender-system/ [accessed on 1 Oct 2020]
- Cosine similarity - https://en.wikipedia.org/wiki/Cosine_similarity [accessed on 1 Oct 2020]
(Header image by free-photos-242387 from Pixabay, released under CC0-license.)

